 AI Agents & Automation
AI Agents & Automation I pointed CC Lens at my home directory last week, expecting a number that would mildly embarrass me. What it returned was an order of magnitude weirder than that.
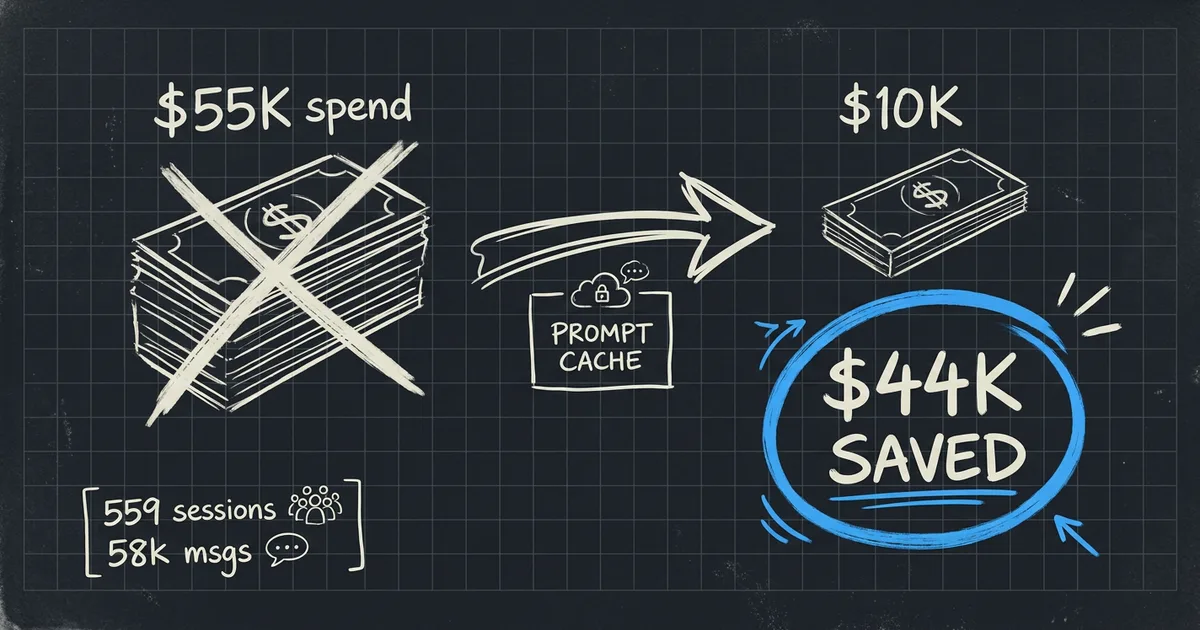
0
sessions
0k
messages
$0k
without cache
$0k
saved by cache
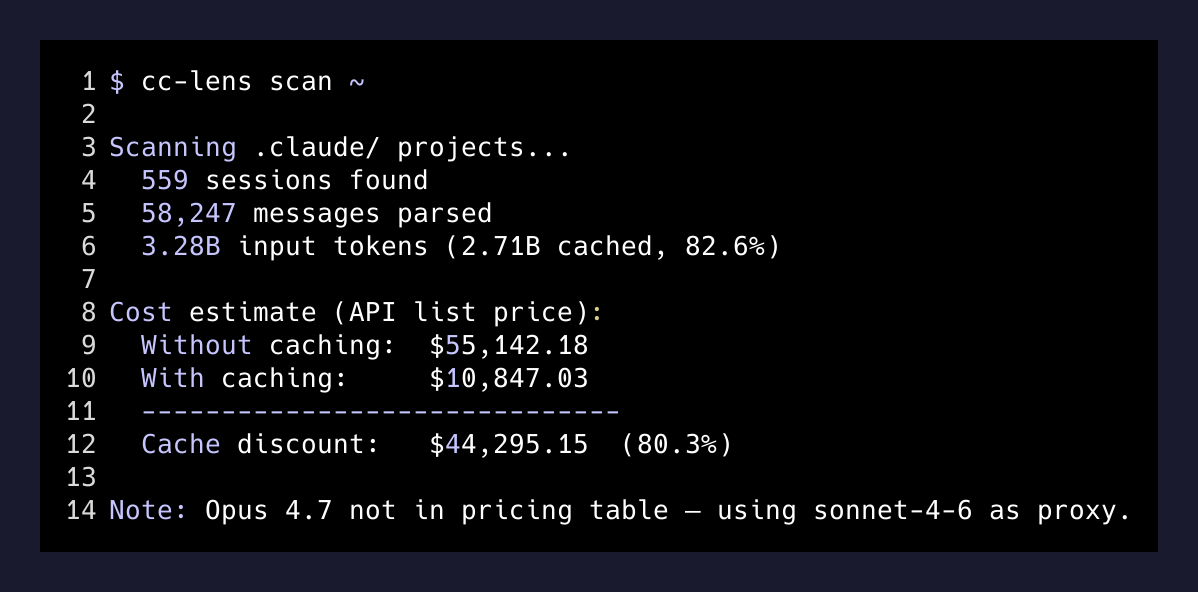
Five hundred and fifty-nine Claude Code sessions. Fifty-eight thousand messages. An estimated $55,000 in API list-price tokens — reduced to roughly $10,000 of “actual” cost because of prompt caching. Forty-four thousand dollars of discount that I never had to ask for, configure, or even understand.
The first thing I did was distrust the number. The CC Lens pricing table didn’t even include Opus 4.7, which is what I run most of the time. The second thing I did was sit with it anyway, because the shape of the number is more interesting than the precision.
What prompt caching actually does
Every Claude Code turn ships a giant prefix to the model: your CLAUDE.md files, the active skill, the system prompt, recently-read files, the tool definitions, the assistant’s own prior turns. On a busy session that prefix is most of the input. The new question at the bottom is usually a rounding error by comparison.
Without caching, you pay full input rate every turn for that whole prefix. With caching, the prefix gets hashed and stored on Anthropic’s side for five minutes. Subsequent turns within that window pay the cache-read rate, which is ~10% of the input rate. A turn that would have cost ten cents costs one.
That is the whole magic. It’s not a “feature” you turn on in Claude Code — it’s just how the client is built. You earn it by reading the same context twice within five minutes, which is what literally any multi-turn agent session looks like.
Without caching, none of this is economically sane. With it, the entire shape of “always-on Claude” becomes affordable for one person.
— Brett Ridenour
Why the number is squishy
The $44k is not money I would have actually been billed. It’s the spread between two list-price calculations using model-pricing tables that may or may not include the model I actually ran. Three honest caveats:
- Opus 4.7 pricing wasn’t in the table at the time of the audit, so any session on that model was being priced against the closest neighbor.
- CC Lens reads local JSONL transcripts, which are an estimate of what the API saw, not the API’s ledger. The Anthropic Console is the source of truth and will tell a slightly different story.
- List price ≠ what you pay when you’re on a Max plan. The $200/mo subscription absorbs a chunk of it. The relevant comparison for me is “subscription cost vs. what I’d owe at API rates,” not “raw token bill.”
What survives all three caveats: the ratio. Cached tokens were on the order of 80% of my input traffic, and they were priced at roughly a tenth of fresh input. That’s not a CC Lens artifact — that’s how the API works.
What this means if you’re building anything multi-turn
If you’re writing your own Claude code — not Claude Code the CLI, but an app that calls the API — and you are not explicitly using cache_control on your system prompt and stable prefixes, you are leaving the same 4-5x discount on the table that Claude Code earns for me automatically.
The actual mechanic from the Anthropic docs is one extra field on a content block:
system=[
{
"type": "text",
"text": "<the giant system prompt + tool defs + reference docs>",
"cache_control": {"type": "ephemeral"},
},
]That’s it. Anything above that breakpoint gets cached for five minutes (or up to an hour with the 1h TTL). Your next turn, as long as the prefix is byte-identical, reads from cache.
A few things that tripped me up the first time I wired this up in a side project:
- The prefix has to be stable to the byte. Inject a timestamp at the top and you’ve cache-busted yourself every turn.
- Order matters. Put the volatile stuff (user message, tool results) below the breakpoint, not above it.
- Caching has a small write premium. First call within the TTL pays ~25% more on the cached portion than a normal input call. You only come out ahead if you’ll read the cache at least twice. For interactive agents, you always will. For one-shot calls, you won’t.
The real takeaway
I started this audit looking for proof I was burning too much money. I left it with the opposite story: an always-on personal AI desktop with 559 sessions on it cost me roughly $10k of token equivalent in a stretch where, at full API rates with no caching, it would have cost $55k.
The interesting bet isn’t “AI is going to get cheaper.” That’s the obvious one. The interesting bet is that the architecture that wins — long sessions, big context, lots of agents reading the same files — is the one prompt caching already subsidizes by an order of magnitude.
The cheap path and the powerful path are the same path. That’s rare. Worth designing around.