I have a video pipeline I’ve been hammering on for the last week. It sits on top of a model I’ve been training and fine-tuning for the last few months — the same one I’ve been quietly running for clients. It ingests a reel, transcribes it, and generates a brief that’s supposed to teach me how to recreate the magic — hook structure, pacing, what the creator did with their hands at the 0:08 mark, the whole thing.
Most of the briefs were fine. A few were great. A few felt off in a way I couldn’t articulate.
That’s the problem with taste. You know when something is wrong. You can’t always say why.
The trick
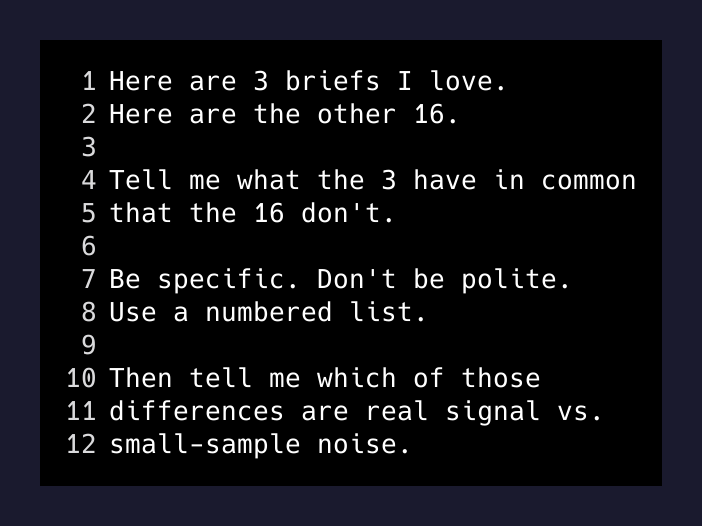
I picked my three favorite briefs out of the batch. Not the three best videos — the three best briefs the system had generated. Then I told Claude:
Here are three briefs I love. Here are the other sixteen. Tell me what the three have in common that the sixteen don’t. Be specific. Don’t be polite.
That’s it. That’s the whole technique. I’m not going to dress it up.
The output was a numbered list. Concrete differences in structure, length, the kinds of references they made, where they put the punchline. About eighty percent of it was useful, twenty percent was noise. Standard ratio.
Then, buried in item six, was this:
The three favorites do not include any “comment GUIDE” or “DM me TEMPLATE” lead-magnet calls-to-action in the brief body. The other sixteen frequently do, even when the source video itself appears to have no such CTA.
That’s a bug. That’s a bug I would not have found in any other way.
What was actually broken
The pipeline lets me hand-edit a transcript before generating a brief. Most of the time I don’t. Sometimes I clean up a misheard word, fix a name, that kind of thing.
Turns out: when a transcript was manually edited, the brief generator was falling through to a fallback prompt that included an old example block. That example block had lead-magnet CTAs in it (“Comment GUIDE”, “DM me TEMPLATE”) because that’s what the source reels in the example block happened to do. The fallback prompt was leaking the example into the output.
The model was dutifully writing CTAs into briefs for videos that had no CTAs. Just because the prompt’s example videos did.
I had no test for this. I had no assertion. I had no eval set. I had a vague feeling that something was off, three favorites I liked, and a question.
Why this works
The reason “compare my favorites to the rest” works is that you almost never write down your taste explicitly. You write specs about behavior — “the brief should be under 400 words, include a hook breakdown, list the visual cues” — but you don’t write specs about the feel of a good output, because the feel is what you can’t name.
Your favorites are the spec you didn’t write. Asking the model to articulate the gap between your favorites and the average is the spec, recovered by induction.
This is the part that got me: the model is better at saying why something is good than I am. I can point. I can’t always explain. The model can read twenty briefs in a single pass, hold all of them in its head, and tell me what the diff is.
I was using it as a code reviewer. I should have been using it as a critic the whole time.
Where else this applies
Once you see this you start seeing it everywhere.
- Writing voice. Pick the three blog posts you wish you’d written, drop them next to your last ten. Ask the model what the gap is. You will get told things about your prose you cannot un-see.
- Code review. Pick three pull requests you’d merge without reading. Compare them against three you’d nitpick to death. The diff is your team’s actual code-quality bar, not the one in the README.
- Hiring. Five resumes you’d interview today. Five you wouldn’t. What’s the actual delta? It’s almost never the one you’d say out loud.
- Design. Three landing pages you envy. Three of yours. The model will tell you what’s missing.
- Customer interviews. Three conversations that energized you. Three that drained you. The pattern is your actual ICP.
The general form is: pick a tiny set you love, a slightly larger set you don’t, and ask for the diff. Three to five on each side is plenty. Specifics beat volume.
The thing nobody mentions about evals
The AI-eval discourse is mostly about graders, rubrics, datasets, scoring. Real engineering. Worth doing.
But before any of that, you have a much smaller question to answer: what does good actually look like for me? And you usually can’t answer it cold. You can recognize it. You can’t generate it.
The favorites-as-spec trick is a way to extract the rubric from your own gut and get it onto the page so you can use it. Once you have the diff in front of you, you can decide which items are real and which are noise. You can drop the real ones into a system prompt as constraints. You can write asserts. You can build the proper eval pipeline.
But you have to find the rubric first. And the rubric is in your taste, not in your head.
What I changed
I fixed the fallback prompt. I added an actual test that runs a transcript edit through the pipeline and asserts the brief has no CTA strings unless the source had one. Five lines.
I also turned the favorites-prompt into a saved skill I can run against any batch of generated content. Three favorites in, gap analysis out. I’ll be running it weekly.
The bug was the surface thing. The technique is the post.
If you build with AI and you ship outputs you have opinions about, try this once. Tonight. With ten of anything you’ve generated this week. You’ll find something. Probably more than one thing.
Your favorites are your spec. You just have to ask.