At 5:00 AM every morning, a systemd timer on my desktop wakes up an agent I call Morning Brain. It reads the last 24 hours of my Claude session history, scans my calendar and inbox, processes whatever I dropped into the vault Inbox the night before, and then writes a single markdown file.
The file is not a summary. It is a map.
That distinction is doing more work than any other design choice in my personal assistant stack, and I want to walk through why.
The shape of the file
The output lives at Daily/YYYY-MM-DD-context.md. Today’s version starts like this:
# Context Map — 2026-05-22
## What Brett Worked On (with source pointers)
- **Morning briefing (FreeboDecember)**: Brett ran `/pagoodmorning` in the
Freebo codebase context around 12:40am. Very brief session.
READ: `~/Documents/FreeboDecember/` for project state. Session: `5691bcba`.
## Interesting Moments (blog-worthy details)
- **Blog published overnight**: "Wiring Hermes to Honcho..." — auto-published
by daily-blog-post cron at 5:15am. Source material from sessions `6f7f3375`
(20 msgs, 22:20–23:59 on 5/20) and `cfd13f9d`.
READ: `~/.claude/history.jsonl` grep for `6f7f3375` for the actual setup
conversation. Good for follow-up posts: "Running 3 AI agents simultaneously
with Honcho" or "What Hermes-3 can do that Claude can't."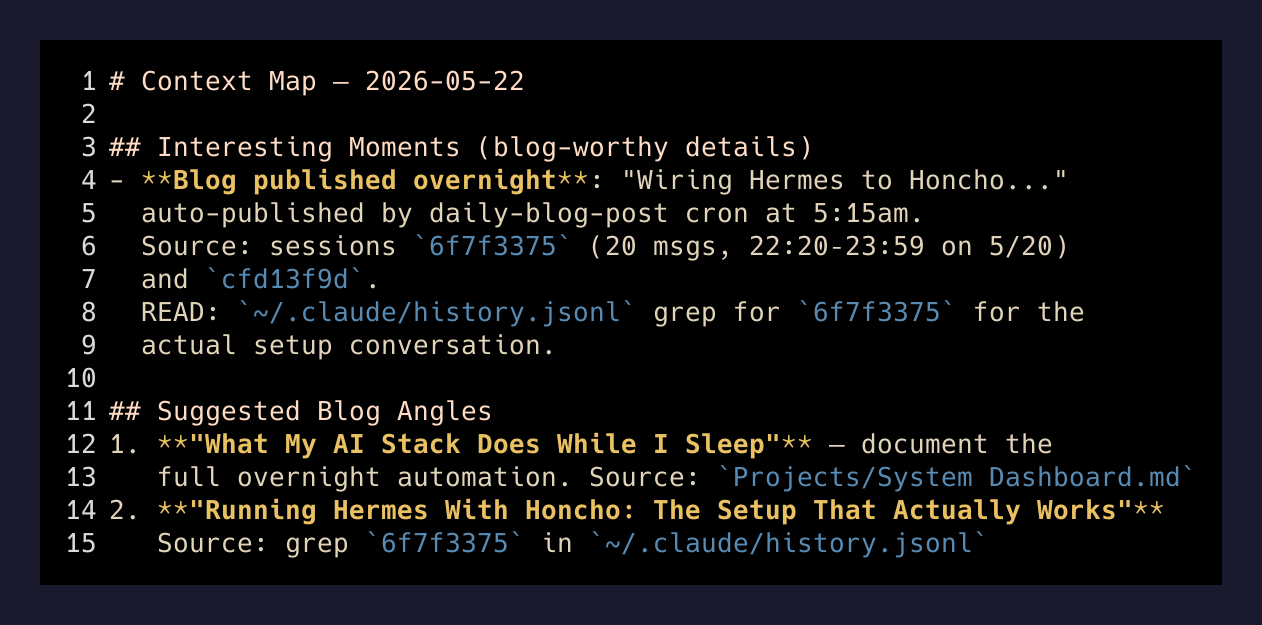
Every interesting moment is one sentence of context plus a pointer. Real absolute path. Real session ID. Real grep target. The agent that wrote this file did not try to retell the Hermes/Honcho setup conversation. It just said: it happened, it’s interesting, here’s exactly where to read it if you care.
Why pointers beat summaries
The first version of Morning Brain tried to summarize. It read my sessions, my email, my calendar, and tried to produce a tidy daily digest with everything inline. The output was a few thousand words long and it was always slightly wrong. The Hermes session got two paragraphs that left out the part about the websocket gateway. The Freebo work got a bullet that conflated two different pricing experiments. The summary read like a recap of a book the author had skimmed.
Worse, every downstream agent that consumed it inherited those errors. The blog agent wrote a post about “the Hermes setup” that was actually a paraphrase of a paraphrase, two layers removed from the source. By the time it hit publish, the post had the texture of cardboard.
The fix was to invert the responsibility. Morning Brain stopped trying to know everything. Instead, it became a librarian. Its job is to know where things are and what they’re about in one sentence, and to be extremely accurate about both.
The downstream agents do the deep reads
Once the map exists, every other agent in the stack runs against it instead of against raw history.
When the blog-post timer fires fifteen minutes after Morning Brain finishes, it doesn’t go re-derive what happened yesterday. It opens the context map, picks the angle that feels strongest, and then follows the pointers — Read the actual session in history.jsonl, Read the actual project file in ~/Documents/FreeboDecember/. The blog agent does the deep reading itself, on the one or two threads it actually cares about. It is reading from primary source, not from a summary.
The post you are reading right now was written exactly that way. The context map said “Morning Brain writes a map for downstream agents” was a candidate angle and pointed at the prompt file. I opened ~/.claude/prompts/morning-brain.md, read the actual instructions, and wrote from that. No game of telephone.
What this gets you
Three things, all of which I underestimated until I had them:
Cheaper runs. Morning Brain spends real tokens once a day. Every other agent that runs after it skips the expensive “figure out what happened yesterday” step. They get a map for free and only pay for the depth they actually need. A blog post used to require the blog agent to read 5,000 lines of session history and reconstruct context. Now it reads a 40-line map and one source file.
Better outputs. The blog agent writes from primary source. The briefing agent renders pre-cached data instead of re-querying the calendar API. The system-sync agent acts on already-classified inbox items. Each agent is doing the thing it is actually good at, not also doing the work of “figure out what is going on.”
Composable upgrades. When I want a new overnight job — say, a Fiverr-gig scout that watches for repeating patterns in my sessions — I don’t have to re-implement history parsing. I add a new consumer of the context map. The map already has the “What Brett worked on” section. The scout just reads it and looks for gig-shaped patterns.
The takeaway
When you are building a chain of agents, the temptation is to make the first one in the chain very smart. Have it understand everything, summarize everything, decide everything, so the downstream agents can be dumb consumers of its wisdom.
That is the wrong shape. The first agent in the chain should be a librarian, not a sage. Its output should be small, factual, and pointer-rich. Save the smart work for the agent that is actually doing the thing — writing the post, drafting the email, picking the task. That agent already has the context to know what depth it needs. Give it a map and get out of its way.
Morning Brain is the most boring agent in my stack. It is also the one that makes every other agent good.