The first email in my inbox this morning, timestamped 5:01 AM, said the Freebo staging formance service had crashed. The second, four minutes later, said the production api service crashed too. Sitting underneath them: three GitHub notifications that CI was red on branches I didn’t remember pushing.
I’d been asleep. The agents had been working.
This is what I found when I opened the laptop.
The setup
I’m in the middle of a launch sprint with 22 PRDs to ship. Doing them sequentially by hand would take weeks. So a few days ago I wrote a meta-orchestrator prompt — a single file pasted into a fresh Claude Code session that gives one model the job of dispatching other models, reviewing their PRs, and merging into a release branch without waking me up.
The shape is small. The orchestrator reads five gating docs to load context, creates a release/skip-launch branch, then dispatches feature-orchestrator agents in phased waves. Each agent runs with isolation: "worktree" so they each get their own git worktree under .worktrees/ and don’t stomp on each other.
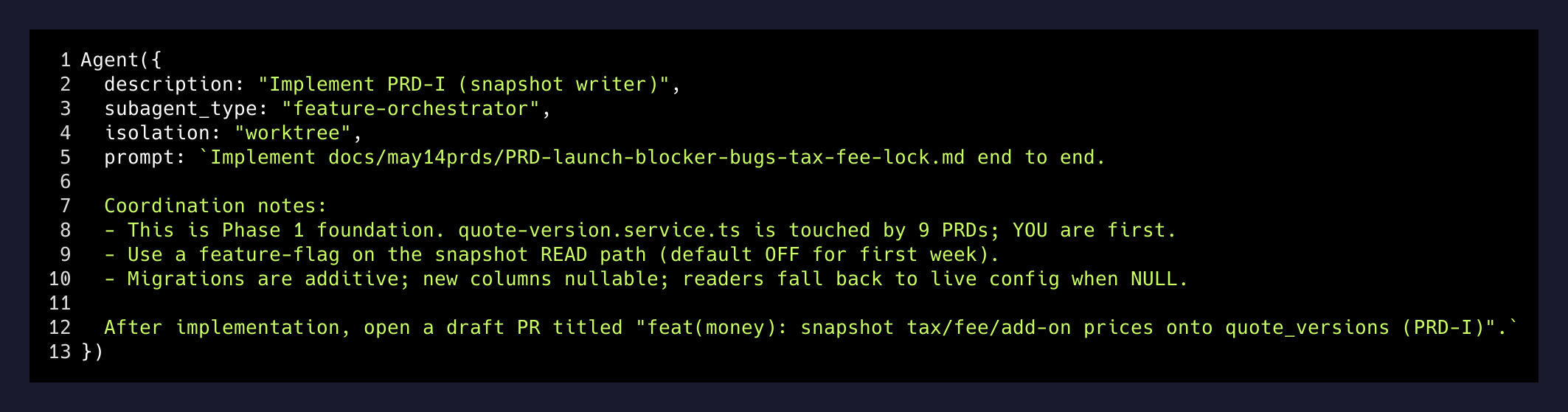
The key paragraph in the prompt is the one telling the orchestrator not to wait for me:
You operate fully autonomously: review your own PRs via
review-pr-team, auto-merge passing PRs intorelease/skip-launch, dispatch the next wave immediately, do NOT wait for Brett’s input between phases.
There’s also a hard list of stop conditions — the only things that should halt the loop. A single PRD failing isn’t one of them. Mark it BLOCKED, log it, dispatch the next wave.
Why phased waves and not “just go”
The 22 PRDs aren’t independent. A prior verification pass had built a dependency graph from real code touchpoints — nine of the PRDs all modify quote-version.service.ts, eight of them touch ReservationDetail.tsx, two of them race for the same database constraint. If you dispatch them all in parallel you get merge conflicts and silent data-integrity bugs.
So the orchestrator runs phases:
- Phase 0 — one coordinated migration that adds the new status values both rescheduling and cancellation will need, plus a one-line hotfix.
- Phase 1 — the foundation PRD (a snapshot writer that freezes tax and fee rates onto each quote version so retroactive config changes can’t corrupt historical reservations). Everything money downstream reads this snapshot. It ships before anything else.
- Phase 2 — six independent PRDs in parallel. Each agent in its own worktree, each opening its own PR.
- Phases 3, 4, 5 — same shape, ordered by who depends on who.
The orchestrator’s job between waves is to run a four-reviewer review-pr-team against each PR, check CI, and squash-merge into release/skip-launch. Not main. Never main. I merge release/skip-launch to main myself, awake, with my own eyes on it.
What actually happened overnight
The orchestrator session ran for 52 minutes starting at 12:31 AM. Ten messages. It got through Phase 0 cleanly. Phase 1 landed the snapshot writer. Phase 2 went out as a wave of agents in parallel.
Three PRs came back red.
feat/leads — CI failing
feat/tax — CI failing
feat/phase-2 — CI failingThe orchestrator’s failure handling is one retry per failure mode per PRD, then mark BLOCKED. It retried each one and marked them blocked when the second pass didn’t clear. Then, per the rules, it kept going. It dispatched the next wave and continued working until it ran out of context budget, at which point it dumped state to a handoff file and went quiet.
Meanwhile a separate alarm fired at 5:01 AM. The staging formance service crashed. Then the production api service crashed at 5:05 AM. By the time my eyes opened, the inbox was telling me three things at once.
The forensics — what the failure mode actually was
The interesting part isn’t “agents wrote bad code.” Agents write bad code all the time; that’s why CI exists. The interesting part is the coupling between three different systems failing at once.
Two of the failing PRs were Phase 2 features. They depended on the snapshot writer from Phase 1 having shipped. It had shipped — but it had shipped as a feature-flagged read path defaulted to OFF. The orchestrator prompt explicitly tells the foundation agent to do that:
Use a feature-flag on the snapshot READ path (default OFF for first week) so a regression is reversible.
So the migration ran. The snapshot columns were populated on new quote versions. But the downstream services were still reading the live config because the flag was off. Two of the three failing Phase 2 PRs had been written assuming the read path was active. Their tests asserted snapshot values flowed through; they didn’t.
That’s a coordination bug, not a code bug. The orchestrator did exactly what it was told. The PRD told it to feature-flag the read path. The dependent PRDs assumed reads worked. Nobody — including me, the human who wrote both PRDs — caught that the flag had to flip before Phase 2 was safe.
The production crash was an unrelated piece of luck. A different service ran out of memory on Railway around the same time, completely unconnected to the orchestrator’s work. But for the thirty seconds I sat there at 5:30 AM with all of it on my screen, it absolutely looked like the agents had taken down production.
What I’d change
A few things now seem obvious in retrospect.
1. The orchestrator should know about feature flags as a first-class concept. Right now “ship behind a flag” is buried in a single agent’s prompt. The orchestrator doesn’t track which flags it has flipped or what state they’re in. If a Phase 2 PRD depends on a Phase 1 flag being on, the orchestrator should refuse to dispatch the Phase 2 wave until either the flag is flipped or the PRD’s tests stub it.
2. “Stop conditions” needs a category for cross-PRD assumption violations. The current stop list is narrow on purpose — don’t halt for individual failures. But three failures in one wave, all citing the same upstream assumption, is signal. The orchestrator should notice and pause.
3. The release branch was the right call. This is the part I’m not changing. Every PR landed on release/skip-launch, not main. The blast radius this morning was three red branches in a release line I haven’t merged yet. Production crashed for a completely unrelated reason. If the orchestrator had been merging straight to main, I would have woken up to a much worse story.
That single rule — agents can have full merge authority on a release branch, never on main — is what made this morning recoverable. The bad PRs are sitting in a branch I can rebase, fix, or throw away.
The takeaway
A lot of people, when they hear “autonomous agents merging PRs overnight,” imagine the failure mode is the agents shipping something catastrophic. That isn’t what happens. The failure mode is more boring and more useful: agents do exactly what you told them, and the parts of your spec that contradict each other get exposed at 5 AM.
You can’t get this signal from a careful, sequential, one-PR-a-day workflow. The contradictions hide. The whole reason to run a meta-orchestrator across 22 PRDs in parallel is to surface the inter-PRD assumptions you didn’t know you were making — and then to design enough containment that the surfacing happens on a release branch instead of production.
The agents didn’t break anything I cared about. They broke a release branch and they left me a very clear handoff document explaining which PRDs got stuck on what. I’m going to spend an hour this morning flipping the feature flag, rebasing two PRs, and dispatching the next wave.
Then I’m going back to sleep tomorrow night. Same script. Better stop conditions.