I was at an AI workshop on Thursday — eleven to two, no laptop, no phone-tethered glances at the build. Three hours of Q&A and slides. By the time I got back to my desk, Claude had merged four branches to main, regenerated the canonical pricing formula hash, and written a Playwright spec that books two real assets against my local Stripe webhook.
I didn’t supervise any of it. I gave it a single markdown file.
The command was /goal docs/prds/v1.goal.md. That’s a Freebo-internal slash command we use for autonomous, multi-phase builds. The whole trick is in the file it points at.
Here’s what I’ve learned writing a few of these now: the model is not the bottleneck. The spec is. If you write the spec the way you’d write a chat message — vibes, suggestions, “make sure to” — the agent runs out of nerve halfway through and stops to ask. If you write the spec the way you’d write a failing test, the agent stays on the rails and ships.
The shape of a /goal file
A good /goal file has five parts, in this order.
1. The mission, in one paragraph. What “done” looks like as a state, not as a task. For this build, the mission line was: “Build the new vertical end-to-end, then prove it works by autonomously configuring two real assets with their actual products, schedules, pricing, and anchor rules, then completing the full reservation lifecycle (book → availability reacts → admin modifies → ledger updates).”
That’s the agent’s compass. Every time it’s tempted to declare victory early, it re-reads this and notices it hasn’t, in fact, run the reservation lifecycle.
2. Required reading, in order. A numbered list of files. The CLAUDE.md, the PRDs, the rollout plan, the data the UAT will load. Numbered, because the order matters — the conventions doc has to be read before any code is written, not in the middle of phase three when the agent finally hits a non-obvious invariant.
3. The phases. Real phase boundaries with real gates between them. This is the load-bearing part.
4. The acceptance spec. One block of prose that lists exactly what the final UAT does, step by step, in numbered order. For this build that was sixteen steps — every one of them an actual thing the agent has to make happen against a running stack.
5. Hard constraints. The invariants that can never break, even temporarily, even mid-refactor. Money in integer cents. Quote versions are immutable. RLS on every new table. Never call Formance directly. These are pulled straight from the project’s CLAUDE.md and re-asserted in the goal file so the agent reads them twice.
Gates are the whole product
Every phase ends with a gate that the agent can run itself. The gate is not “make sure it looks right.” The gate is a list of shell commands and assertions.
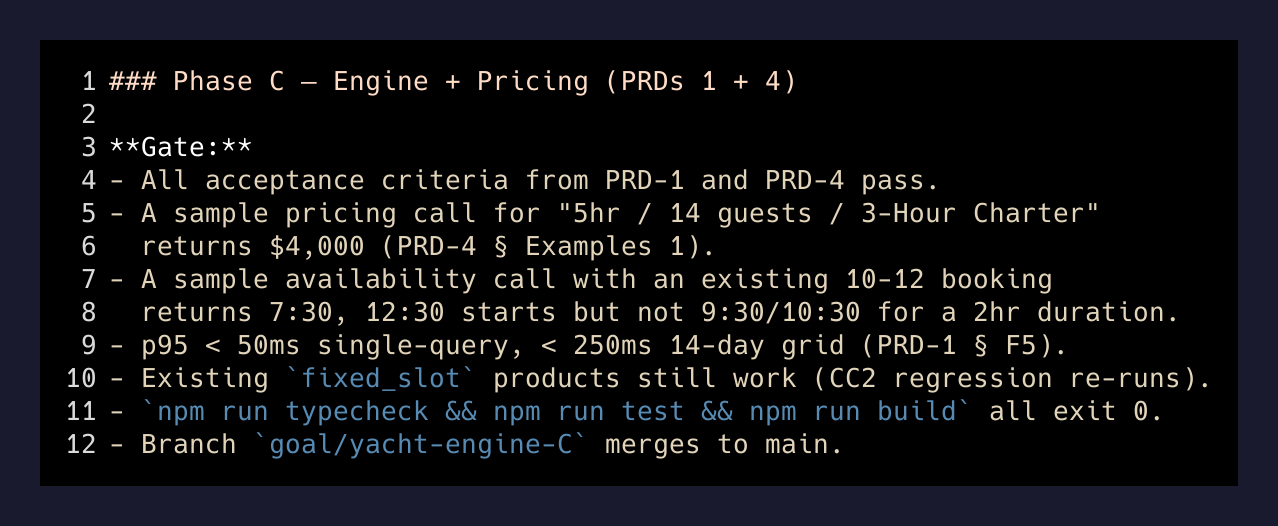
That’s a real phase gate from the file. Notice what’s in it:
- A typecheck + test + build chain that must exit 0.
- A bit-for-bit hash comparison of a canonical pricing formula (the “CC1” invariant — that one function is the entire money model, and if its byte sequence changes during a refactor, every booking on the platform is suspect).
- A 100-fixture regression suite that exists separately from the unit tests, specifically because unit tests pass after refactors that subtly change semantics.
- A worked example with the actual expected output: a 5-hour charter at 14 guests on the 3-Hour Charter product returns exactly $4,000.
- A p95 latency budget. 50ms single-query, 250ms for a 14-day grid.
- A branch name. Each phase merges to its own branch first, then to main, in order.
If any one of those fails, the rule is: do not proceed. Fix on the same branch and re-run until green. The agent doesn’t get to negotiate. It doesn’t get to ship “mostly green.” It either passes the gate or it stays on the branch.
That’s what makes the whole thing safe to run unattended. A failing typecheck halts phase B. A pricing formula whose hash changed halts everything. The agent can’t accidentally barrel through a regression because the next phase’s first action is re-running the previous phase’s gate against main.
The trick: the agent writes its own UAT
The final phase’s gate is the one I’m most proud of. The agent writes a Playwright spec called e2e/uat-v1.spec.ts and the gate is “all sixteen steps pass headless.”
A flavor of what the steps look like:
1. Sign up a new operator. Create a fresh test location.
2. Create the first asset from its specs.md file.
3. Create the products. Pull descriptions from the markdown.
4. Configure pricing from a CSV matrix. Verify worked
examples — totals must match the algorithm doc.
5. Configure availability rules (operating window,
sunset reserve_window, minimums, lead time).
6-9. Same for the second asset.
10. Customer books asset #1 in incognito. Stripe test card.
Wait for the BullMQ worker to drain. Verify ledger event.
11. Re-query availability — booked window is gone.
12. Admin modifies the reservation. Verify a NEW quote_version
row was inserted (immutability invariant).
13-15. Second asset booking, cancellation, cross-asset rule.
16. Regression: fixed-slot kayak still books unchanged.The agent is the test author and the test subject. It builds the feature, then writes a script that books the feature, then runs the script, then doesn’t get to claim victory until the script passes. The honest part is that step 16 is the one I trust most — it’s the kayak product, untouched, the thing that was already shipping. If the agent’s refactor accidentally broke that, the whole build is rejected even if all fifteen new-vertical steps pass.
What this changes about working with AI
Most “AI is autonomous now” demos are autonomous for the wrong fifteen minutes. The agent makes ten decisions you didn’t see, then asks you about the eleventh, and you’re back to being a supervisor with PTSD.
A self-grading spec inverts it. You spend two hours up front writing the criteria. The agent spends six hours executing against them. You spend twenty minutes reviewing the final PR. The ratio of your time to its time is the whole point.
The thing nobody warns you about: the hard part isn’t getting the agent to work. It’s writing a spec that’s specific enough that “done” is a calculation, not a judgment call. “Make the booking flow work” is a judgment call. “A 5-hour 14-guest 3-Hour Charter returns $4,000 from /products/:id/quote” is a calculation. The agent can grade itself on calculations all day.
If you want to try this on your own project, the entire thing collapses to one rule: don’t write a spec the agent can interpret. Write a spec that interprets the agent.