There’s a version of AI-assisted development that looks like this: you type a prompt, review what comes back, type a correction, review again, steer, nudge, repeat until it’s good enough. That’s fine for small things. It doesn’t scale to building a boat booking vertical with multi-tier pricing, flexible duration windows, cross-asset availability rules, and double-entry accounting.
For that, I write a gate file.
What a Gate Is
A gate is an explicit, machine-checkable condition that must be true before the next phase of work begins. Not “looks good to me” — a hard criterion. Specific numbers. Specific test assertions. Green CI.
For Freebo’s boat feature, one gate looks like this:
Gate (Phase C — Engine + Pricing):
- A sample pricing call for "5hr / 14 guests / 3-Hour Charter" returns $4,000 (PRD-4 § Examples 1).
- A sample availability call with an existing 10–12 booking returns 7:30, 12:30, etc. starts
but NOT 9:30/10:30 for a 2hr duration (PRD-1 § Examples).
- p95 < 50ms single-query, < 250ms 14-day grid.
- Existing fixed_slot products still work (CC2 regression re-runs).
- npm run typecheck && npm run test && npm run build all exit 0.
- Branch goal/boat-engine-C merges to main.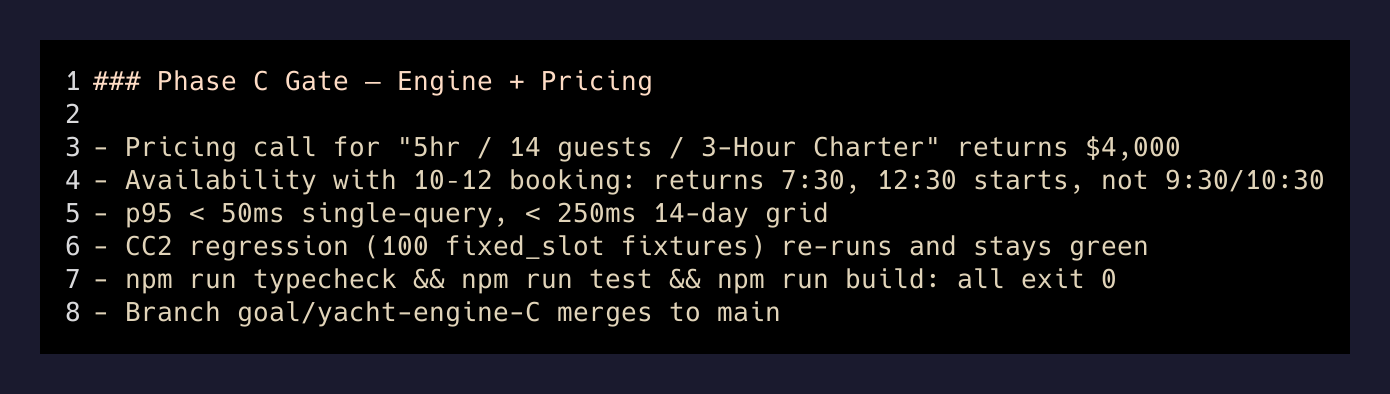
The model can’t move to Phase D until all of that is true. Not one piece of it — all of it. If Phase C’s gate fails, it fixes the branch and re-runs. It doesn’t ask me what I think.
The Spec File
The boat v1 build runs from a single file: docs/prds/boat/boat-v1.goal.md. You run it with:
/goal docs/prds/boat/boat-v1.goal.mdThat’s the whole interface. What the file contains is the actual work.
The file defines five sequential phases (strategy foundation, schema migrations, pricing engine, availability rules, checkout + visualizer), each with its own branch name, gate criteria, and required reading. It also defines five cross-cutting constraints — CC1 through CC5 — that apply across every phase:
- CC1: The pricing formula sequence in
quote-version.service.tsmust be bit-for-bit identical before and after. Hash the file at the start of each phase. Hash it at the end. They must match. - CC2: A 100-fixture regression for existing fixed-slot products must be green at every phase merge.
- CC3: Every new database table must have a passing RLS test.
- CC4: No raw SQL anywhere in
apps/api/src/strategies/. - CC5: A 16-step end-to-end UAT spec, written and run by the model, must pass headless.
The money-related constraints are the interesting ones. Freebo stores all prices in integer cents and routes every financial operation through an event emitter → BullMQ queue → a worker process → Formance (a double-entry accounting ledger). No direct calls to Formance from routes. No floating point. No mutating existing quote versions — any price change creates a new immutable row and updates a foreign key pointer. These aren’t preferences. They’re invariants, and the spec file names them by name so there’s no ambiguity about what “don’t break money” actually means.
The UAT Spec
The CC5 test is where the spec file gets strange.
I don’t write the Playwright test. The model does, using the spec as instructions. But the instructions are specific enough that there’s only one way to write it correctly. Here’s a slice of what the spec tells it to build:
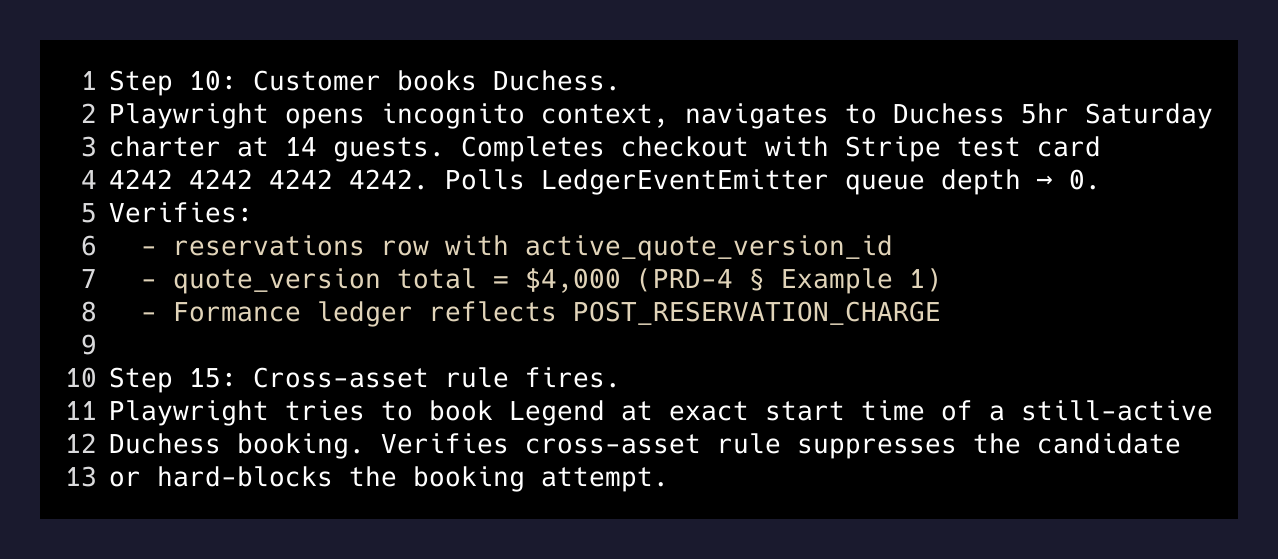
Step 10: Customer books Charter A.
Playwright opens an incognito context, navigates to the public booking page
for a Charter A 5hr Saturday charter at 14 guests. Completes checkout with
Stripe test card 4242 4242 4242 4242. Waits for the BullMQ worker to drain
(poll LedgerEventEmitter queue depth → 0). Verifies:
- A reservations row exists with the expected active_quote_version_id.
- The quote_version row total matches PRD-4 § Example 1 ($4,000 for
5hr/14-guest/3-Hour Charter).
- Formance ledger reflects POST_RESERVATION_CHARGE (query Formance API
for the transaction).The test knows to poll queue depth before asserting anything about the ledger. It knows the expected dollar amount. It knows to verify the Formance transaction, not just the database row. These details are in the spec because I put them there — the model didn’t invent them. But the model translates them into a working Playwright spec and then runs it.
Step 15 is the one I like best:
Step 15: Cross-asset rule fires.
Playwright tries to book Charter B at the exact start time of a still-active
Charter A booking on the same Saturday. Verifies the cross-asset rule suppresses
the candidate or hard-blocks the booking attempt.That’s testing a rule that says: if Charter A is booked at 2pm, Charter B can’t start at 2pm because both boats share the same dock. The model has to configure that rule (step 9), then write a test that proves it fires (step 15), then actually run the test against a running local stack. All without me touching the keyboard.
Why This Is Harder Than It Sounds
Writing this spec file took longer than the first three phases of actually building the feature. That’s not a complaint — it’s the point.
When you write a gate, you’re forced to define “done” in terms the machine can verify. You can’t write “pricing looks right.” You have to write the exact dollar amount and which endpoint returns it. You can’t write “availability is correct.” You have to specify which start times should appear and which ones shouldn’t, given a concrete booking scenario.
That forcing function is useful. Half the bugs in software start as vague requirements that made sense when someone said them out loud and broke down the moment someone tried to implement them. Writing the gate is where vague requirements become precise ones.
The other thing the spec file does is create a reusable artifact. If I want to run the build again from scratch — on a new database, on a new branch, for a new client — I run the same file. The spec doesn’t drift with the codebase the way a Notion doc does. It references the PRDs, and the PRDs are versioned with the code.
What the Model Actually Does
When you run /goal, the model reads the spec and starts working through it. It calls /feature-orchestrator for each phase, which in turn decides whether to run /upgrade-feature-team or /implement-feature-team based on whether it’s modifying existing systems or building new ones.
Each team is a set of agents that work on different layers: one for database migrations, one for API endpoints and TypeScript types, one for the frontend. They run sequentially because each layer depends on the previous one — you can’t write the React hook before the endpoint exists.
At the end of each phase, the model runs the gate checks. If anything fails, it stays on the branch and fixes it before merging. It doesn’t ask me for help. It either passes the gate or it doesn’t.
When all five phases have merged and CC1 through CC5 are green, it posts a PR summary with a list of every merged branch, the Playwright UAT trace, and a note on any pricing rules from the real boat spec sheets that couldn’t be encoded (the target is zero gaps).
I read the summary. If the gates all passed, I merge.
The Takeaway
The spec file is the hardest part of the job. Writing it well means knowing your domain well enough to define “done” precisely, knowing your architecture well enough to name the invariants, and caring enough about correctness to write 16 UAT steps instead of “test the booking flow.”
Once it’s written, the build is almost mechanical. Not completely — the model occasionally makes a wrong turn, and the gate catches it — but the human creative work happens in the spec, not in the code review. That’s a different job than I was doing six months ago. I’m not sure it’s easier, but it’s definitely more interesting.
If you’re using AI to write code and you’re still spending most of your time reviewing and steering, try writing the gate first. Figure out exactly what “done” means before you start. The prompts get shorter. The results get better. And you end up with something you can run again.