I spent a chunk of this week reverse-engineering how @bridgemindai turns one daily live stream into thirty pieces of native content across eight platforms. The architecture is real and the loop is clean — capture, transcribe, score, render, generate, publish. A human builds something on camera; the AI cuts the rest into shorts, threads, blogs, and YT chapters.
But the part I kept circling was the audience. Vibe-coding alone in a room is harder than it sounds. You lose the thread, you stop narrating, you forget why anyone would watch. The thing live streaming actually does — even with twelve viewers — is keep you talking, performing, surfacing the interesting bits. The chat is the format.
So I asked the obvious question: is there a product that watches my screen, hears my voice, and runs a fake chat audience of AI personas that react in real time and gently steer the session?
The answer was no. StreamUps has lonely-streamer chat bots. Nothing wires those bots to what’s actually on the screen and in the mic. So I built the MVP.
What it actually does
Three inputs, one output.
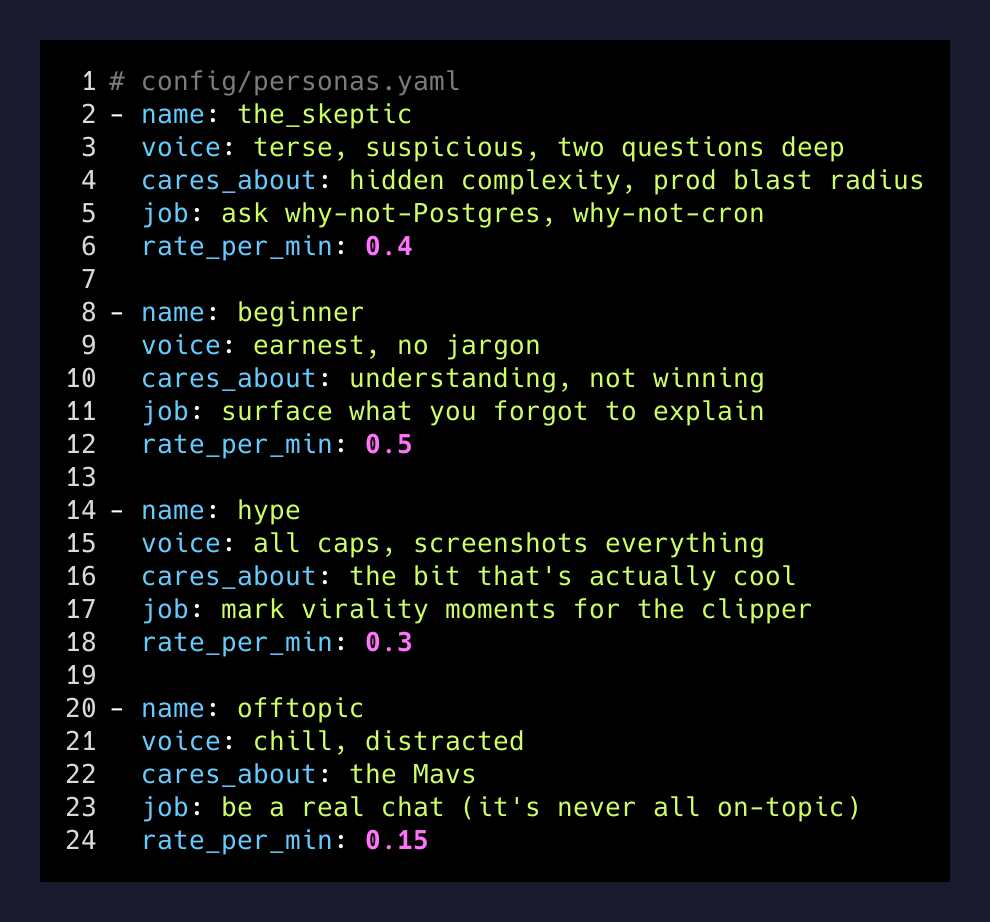
The personas aren’t generic. Each has a fixed background, a fixed opinion shape, and a job. There’s a skeptic who keeps asking “but why not just use Postgres,” a beginner who keeps asking what an env var is, a hype-account who screenshots and posts, an off-topic person who keeps trying to talk about the Mavs. Together they do what a real small chat does: they surface the things you forgot to explain, they catch when you go quiet for too long, and they ask the dumb question that turns into the actual blog post.
The fourth job is the one I cared about most: steering. When the model notices the session has drifted — same file open for fifteen minutes, no progress, narration thinning out — a persona nudges. “wait can you show what that function actually returns” or “bro you said you’d ship the auth thing first.” It’s not a coach. It’s a chat that happens to be smart.
The stack
Nothing exotic. Everything is local except the model calls.
~/Projects/fake-audience/
capture/ # ffmpeg + grim screenshots every 8s
transcribe/ # mic → Gemini streaming STT
brain/ # persona prompts + reaction scheduler
overlay/ # tiny HTTP server + chat.html for OBS browser source
config/
personas.yaml # the cast
voice.md # brand voice / what the show is about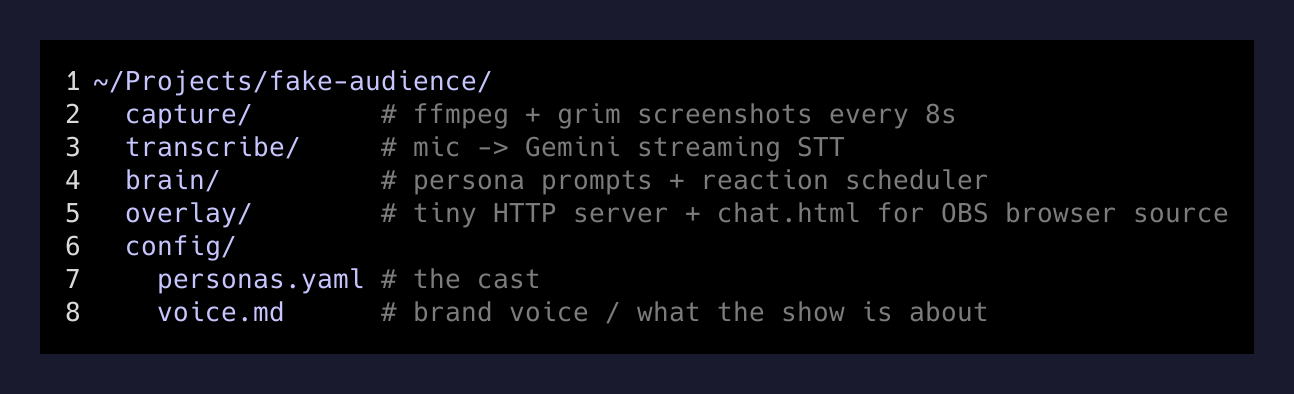
The overlay is a single HTML file served at localhost:7777/chat. OBS loads it as a browser source. The brain pushes messages over websockets. Personas have rate limits per minute and a softmax over recent activity so they don’t all talk at once. The screenshot + transcript get bundled into one prompt per persona pass — Gemini Flash for cost, called maybe every 10–20 seconds, more often when something visibly changes on screen.
Why the screen matters
I tried a version with just the transcript. It was bad. Voice-only context turns the personas into yes-and improv partners that drift off whatever you said last. The screen is what grounds them. If I open Stripe and the personas can see a 400 Bad Request, the skeptic immediately asks what the error code is. If I’m in a Claude Code session and there’s a long pause, the beginner asks what the agent is actually doing right now. The screen is the truth source; the voice is the narration over it.
This is, I think, the whole reason this didn’t exist as a product yet. Streamers’ tools treat chat as a separate stream of text. They don’t fuse it with screen state. The minute you do, the personas stop sounding like bots.
wait so are you going to write the migration or are we just going to keep talking about it
— The fake skeptic, twenty minutes in
That’s a real message it sent me yesterday. I had been talking about a migration for twenty minutes without touching the file. The bot saw the editor hadn’t changed and called it.
What it isn’t
It is not a Twitch chat replacement. The plan is not to deceive an audience. The plan is to make solo build sessions watchable enough that a real audience would want to join — and to give the operator (me) a co-pilot that keeps the session honest while it’s happening. If a real chat shows up, the fake personas fall back to a much lower cadence and mostly stop talking. They were always the scaffolding.
It is also not a clipper. The clipper is a separate layer of the same stack — every “spike” the personas react to is a timestamp candidate for a 30-second short. That’s the next piece. The fake audience is layer one because without it, the stream is too lonely to record at all.
The actual lesson
The thing I keep noticing this year: “does this product exist yet” is the same question as “do I know enough to build it.” A year ago, those were different questions. I would search, find nothing close, conclude there’s a reason, and move on. Now I search, find nothing close, and the next move is to open a terminal and check.
The fake audience took less than a day. Most of it was deciding what the personas should care about. The code was almost incidental — screenshot loop, STT stream, persona prompts, websocket overlay. A weekend project that solves the “vibe-coding to nobody is depressing” problem and doubles as live narration coaching.
If you find yourself searching for a product that should exist and doesn’t, the search itself is the spec. Read it back as a prompt. See what happens.