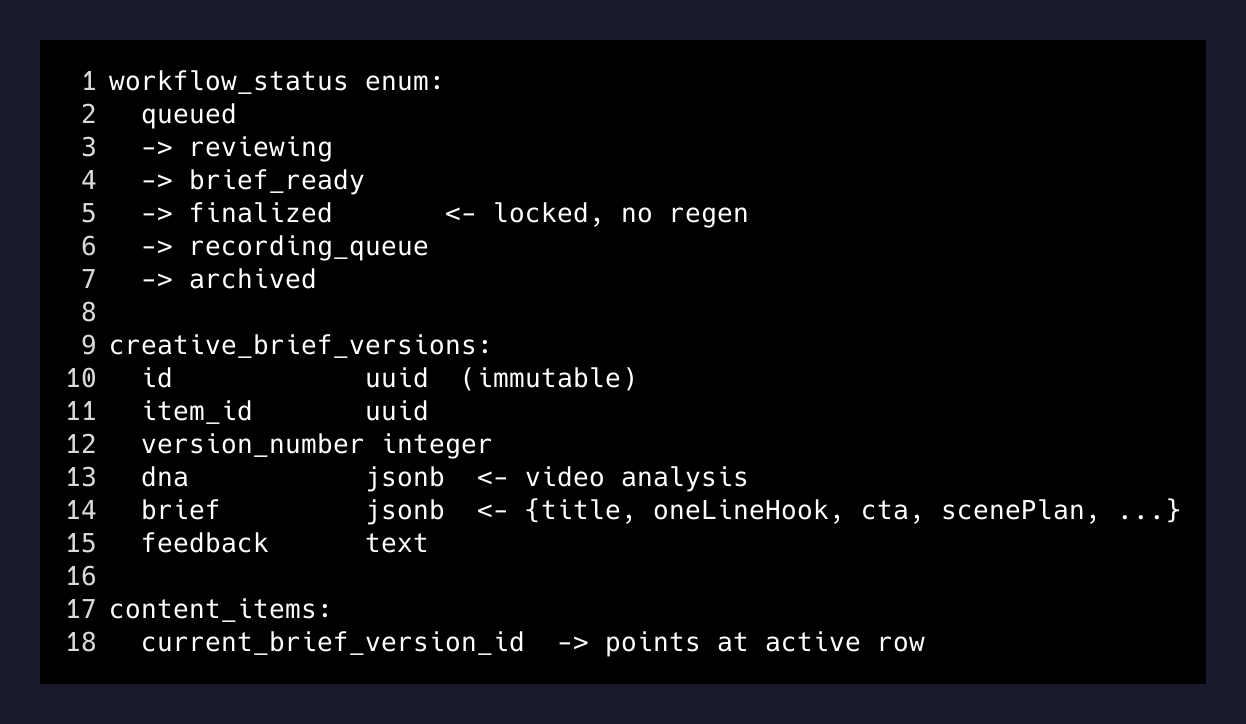
The workflow design was intentional. queued → reviewing → brief_ready → finalized → recording_queue → archived. Clean state machine, one direction. Brief versions are immutable — every refine writes a new creative_brief_versions row, never mutates the existing one. The kind of schema you write when you’ve been burned by mutable content before.
Then I had a batch of finalized briefs that needed a surgical edit. The rule had changed: no more in-video CTAs. Remove every “DM me” from every locked script. Fix a stale funding number on a handful more.
The API couldn’t do this. Not cleanly. That turned out to be a design insight worth writing down.
Why the API fails here
ReelForge’s API is built around managed state transitions that almost always involve AI. You submit a reel URL, it downloads and queues. You trigger analysis, Gemini reads the video and populates a dna JSON object — hook structure, pacing, visual style notes, strong moments. You generate a brief, the model writes the script against your brand profile and the video’s DNA. You refine, the model revises based on your feedback, and a new version row gets written.
Every action through the API is, potentially, an AI action. That’s the point of the abstraction.
The immutable version history is good design. If I want to improve a brief, I should refine it and get a new row — because the model has context I’ve added since the last version, and “improve this” deserves a fresh synthesis, not a patch on the old text. The old version stays in history. Nothing gets overwritten.
But regeneration isn’t a copy-with-minor-changes. It’s a new pass. The model writes something reasonable, but it doesn’t know what made the last brief good. The hook phrasing that felt sharp, the specific scene timing, the angle I’d added context about in the Q&A — all of that is nominally preserved in the dna and the feedback field, but it doesn’t survive a regeneration intact. You get maybe 80% of what you had.
Sending a “remove the DM CTA” feedback message through the refine endpoint would have touched every brief. I’d have gotten 30 new briefs that were approximately as good as the ones I started with, minus the “DM me” line. That’s a lot of quality variance for a three-word edit.
What I did instead
I opened a shell and went around the abstraction.
docker exec -it supabase_db_reelforge-studio \
psql -U postgres -d postgresThe brief column on creative_brief_versions is JSONB. The CTA lives at brief->>'cta'. Surgical update, one query:
UPDATE creative_brief_versions
SET brief = jsonb_set(
brief,
'{cta}',
to_jsonb(regexp_replace(brief->>'cta', '\sDM\s+me\b[^.]*\.?', '', 'gi'))
)
WHERE id IN (
SELECT current_brief_version_id
FROM content_items
WHERE workflow_status = 'finalized'
)
AND brief->>'cta' ILIKE '%DM me%';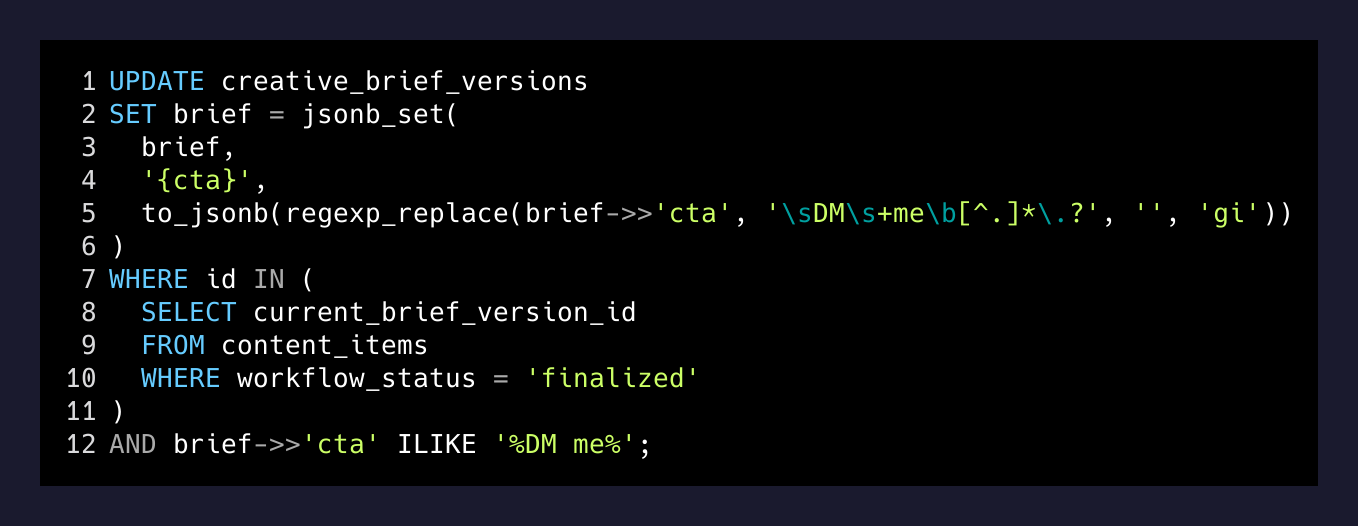
Thirty rows. Done. No regeneration. The hooks are where they were. The scene timing is where it was. The angles are intact. The only thing that changed is the field that needed to change.
The distinction that matters
There are two kinds of changes you make to AI-generated content:
AI operations — anything where the content itself needs to evolve. New angle, structural feedback, length adjustment, tone shift. These should go through the API. You want a new version row. You want the model to synthesize against your feedback. You want the audit trail.
Data operations — anything where the content is correct but a specific field needs patching. CTA swap. Number update. Brand name change. Typo fix. These are not model operations. They are text operations on a predictable field in a known schema.
The mistake I almost made was treating the second category like the first. The refine endpoint reads your feedback as an invitation for synthesis. “Remove the DM CTA” sounds like a small instruction, but to the model it’s a prompt to reconsider the entire closing sequence, and probably a bit of the structure around it.
The right move was to reach past the abstraction.
When this doesn’t work
This only holds if you understand your own schema. I knew the brief field is JSONB with a consistent shape — cta is always a top-level string, always structured the same way, across every brief version ReelForge writes. The regex was safe.
If the schema were ambiguous, or if the field were structured differently per record, the direct edit would be riskier than a regen. And there’s an audit trail cost: direct DB writes don’t create a new creative_brief_versions row, so you lose the version history for those changes. For a CTA strip, that tradeoff was obvious. For something more substantive, I’d want the version.
The broader point
Building good API design means locking down the paths that should go through AI. But “go through AI” and “edit the data” are not the same thing, and treating them as synonymous is how you end up regenerating 30 scripts to change three words.
Know where your abstraction ends. Know what’s a model operation and what’s a data operation. And know the psql command to get there when you need it.
Sometimes the right engineering decision is to skip your own API.