A few days ago I posted about wiring Hermes up to Honcho so my terminal agent would finally remember me between sessions. The setup looked clean. Systemd unit running, gateway responsive, messages flowing in. I declared victory and moved on.
It was lying to me.
When I went back to check what Honcho actually knew about me — I had been chatting with the agent for days at that point — the answer was nothing. Zero observations. Zero conclusions. Just a queue of 31 unprocessed “representation units” sitting in Postgres, waiting for a deriver that was running but not actually deriving.
Here is the chain of three bugs I had to unwind before the agent’s memory came online.
Bug 1: the deriver was batching itself into a corner
Honcho is built around a background worker called the deriver. It reads from a queue of conversation units, groups them, then asks an LLM to extract observations (“user lives in Austin”) and conclusions (“user does not want auto-prioritization”) about the user. Those go into a vector store the agent can query later.
The deriver was running. The queue had stuff in it. Nothing was getting derived.
The reason was a config default that makes total sense for a multi-tenant SaaS and zero sense for a single-user PA: representation work only flushes when the batched token count hits a max. Default REPRESENTATION_BATCH_MAX_TOKENS=1024. My biggest single unit was 937 tokens. The deriver would batch one unit, sit at 937, wait politely for a second unit to push it over 1024, and never get one because conversations end.
It was a queue full of conversations that were each individually too small to ever flush, and collectively never close enough together in time to combine.
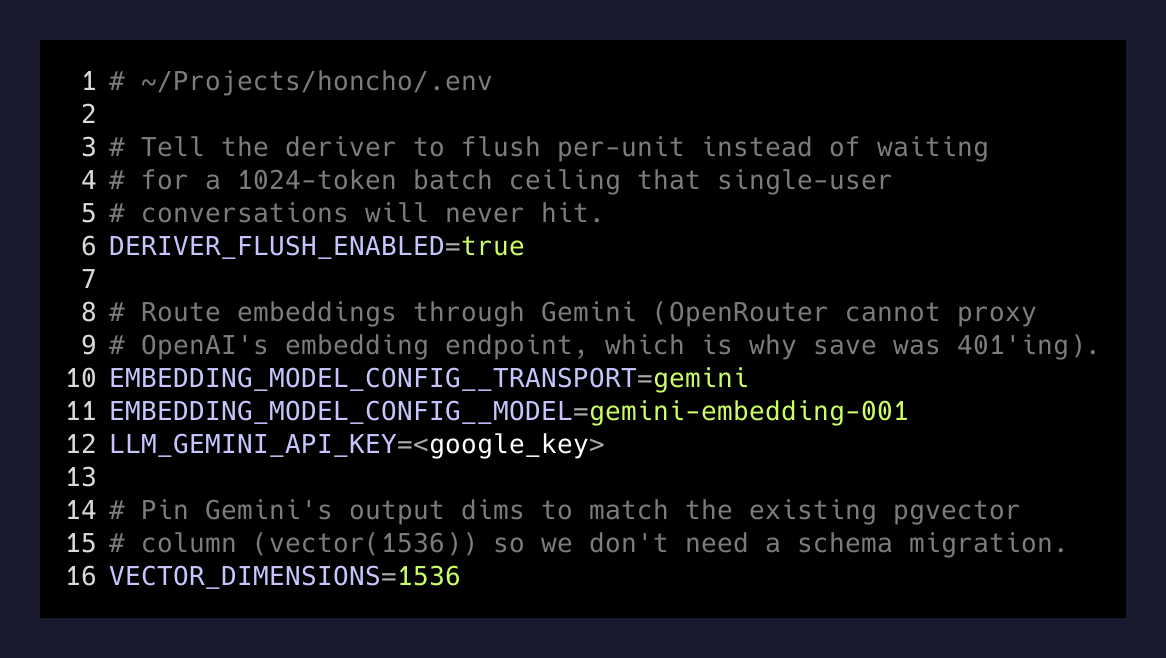
The fix was one environment variable:
# ~/Projects/honcho/.env
DERIVER_FLUSH_ENABLED=trueThis tells the deriver to process whatever it has at the end of a unit instead of waiting for the batch ceiling. For a single-user agent this is the right default. For a 10,000-user SaaS it would torch your LLM bill. I get why the default is what it is — but Honcho’s deployment docs could stand to flag this for self-hosters.
Bug 2: a 401 from OpenAI for a request I never sent to OpenAI
Restart the deriver, watch the queue actually start moving. The LLM call to extract observations runs. Then the save step blows up:
401 Unauthorized — Incorrect API key providedWhich is funny, because the OpenAI key I had in .env was an OpenRouter key (sk-or-v1-...). It worked fine for the deriver’s reasoning calls — those were going through OpenRouter to a Haiku model. So why was something 401’ing?
Because saving an observation requires embedding it. And Honcho’s embedder, by default, calls OpenAI’s embedding endpoint directly — bypassing the routing layer entirely. OpenRouter cannot proxy OpenAI’s embedding API. My key was being sent to api.openai.com/v1/embeddings where, as far as OpenAI is concerned, sk-or-v1-anything is just a malformed string.
So I had two different LLM providers wired up to one config slot and the deriver was reaching for whichever one fit each call. Embeddings: OpenAI directly. Reasoning: OpenRouter. The error message blamed the key. The actual problem was the routing.
Bug 3: switching providers without breaking the vector column
The fix to bug 2 was to stop routing embeddings through OpenAI at all. I had a Google API key already set up for Gemini, so I switched embeddings over:
EMBEDDING_MODEL_CONFIG__TRANSPORT=gemini
EMBEDDING_MODEL_CONFIG__MODEL=gemini-embedding-001
LLM_GEMINI_API_KEY=<google_key>Restart the deriver. Watch a unit get embedded. Watch the database write fail.
ERROR: expected 1536 dimensions, not 3072Right. Embedding models have native output dimensions. OpenAI’s text-embedding-3-small is 1536. Gemini’s gemini-embedding-001 is 3072 native. Honcho’s documents table was created with a vector(1536) column — that is the schema the migrations wrote on day one when I was still on OpenAI.
Two ways out:
- Drop and recreate the column at 3072 dims, lose any embeddings already in there.
- Tell Gemini to output at 1536 dims, which the model supports as a configuration option.
Honcho exposes that as VECTOR_DIMENSIONS=1536, and when set, it passes output_dimensionality=1536 to the Gemini call. Gemini truncates and renormalizes server-side. The vector column is happy. The deriver is happy.
VECTOR_DIMENSIONS=1536One line. Saved me a migration.
The result
After all three fixes were in, I forced the queue to re-process the stuck units:
UPDATE queue SET processed = false WHERE processed = true;The deriver picked them up. Thirty-one out of thirty-one processed. 99 observations and 96 conclusions about me, derived from a week of casual conversation with the agent.
I queried Honcho directly to see what it learned. The answers are surprisingly accurate:
- I have ADHD and need bounded tasks
- I go to bed before midnight on weeknights
- I dislike auto-reprioritization — I want to control my task order manually
- I use a specific set of command phrases when delegating work
- My calendar lives in Google Calendar and Todoist holds the truth on tasks
None of that is in any prompt I wrote. The agent inferred it from how I talked to it.
What I’d tell past me
- Day 1Wire it upFollowed the docs, everything green. Did not verify anything had actually been derived.
- Day 4Check the queue31 units stuck. Realized 'service is running' is not the same as 'service is working.'
- Day 4 +1hFix flushSet DERIVER_FLUSH_ENABLED=true. Queue starts moving. New error appears.
- Day 4 +2hFix embeddings providerOpenRouter key cannot proxy OpenAI embeddings. Switch transport to Gemini.
- Day 4 +3hFix dimensionsPin VECTOR_DIMENSIONS=1536 so Gemini matches the existing pgvector column.
- Day 4 +4hRe-processFlip processed=false on the stuck queue rows. Deriver picks them up. 99 observations land.
The pattern across all three bugs is the same: a default that is correct for the most common deployment shape (multi-tenant, OpenAI-native, fresh database) but wrong for mine (single user, multi-provider, schema already locked in). None of these are bugs in Honcho. They are the seams where one set of assumptions meets another.
Self-hosting any non-trivial service means owning those seams. The docs will get you to “running.” Getting to “actually working” is a debugging sport, and the score is kept in the queue table.
The most important habit I picked up from this: after wiring any background worker, query the thing it is supposed to produce. Not “is the process up?” Not “is the queue empty?” Did the artifact you actually care about — the observation, the embedding, the row — appear? If not, the service is decorative.
My agent remembers me now. It took three days longer than I thought it would. The next agent I wire up to memory will take three hours, because I know which questions to ask before I declare victory.