Yesterday morning my staging deploy was down.
I noticed because a script that pings the health endpoint started failing, and instead of getting a 200, I got the kind of empty silence that makes you sit up straighter. No 502. No 503. No “Application failed to respond.” Just a connection that opened, stared at me, and closed.
The first thing I did — and this is the part I want to talk about — was assume I broke it.
The story I told myself
I had a story already loaded. A few weeks ago I’d been moving some payment methods around. There was a card that expired. I remembered seeing an email from Railway about a billing thing and clicking through it half-asleep. I had no memory of what I’d actually done.
So when the deploy went dark, my brain produced a finished narrative in about four seconds:
You forgot to update the card. Railway suspended the service. You did this.
Beautiful. Causal. Wrong.
But it had the two properties a bad assumption needs to survive: it explained the symptom, and it made me the author of my own problems. Which felt right, because I am usually the author of my own problems.
I spent the next forty minutes inside the Railway dashboard. I rotated billing. I checked the service logs (clean, then nothing). I re-deployed from the latest commit. I checked the GitHub integration. I rolled back to a known-good build. I opened a support ticket. I considered whether some railway.toml change I’d made days ago had quietly broken cold starts.
None of it worked, which only made me more sure the problem was me. If a build won’t deploy, the build is broken, right? If the build worked yesterday and not today, something I changed must have done it.
If a build worked yesterday and not today, something I changed must have done it.
— Me, to myself, while tearing apart a config that wasn't broken
What was actually happening
Around the time I was about to start bisecting commits, I refreshed Hacker News on the other monitor and saw it on the front page:
Incident Report: Railway Blocked by Google Cloud (Resolved)
The TL;DR was: Google Cloud’s automated abuse systems had flagged Railway’s billing account and frozen a significant chunk of their GCP infrastructure. This is not “Railway is having a bad day.” This is “the platform your platform runs on temporarily kicked you out of the building.” Railway’s engineers spent hours getting GCP to unfreeze the account. While that fight was happening, deploys in certain regions silently failed in exactly the way mine had — connections that open and close, no useful error message anywhere in the stack.
Forty minutes of dashboard archaeology. The actual fix was: wait.
The trap is called false attribution
There’s a name for this. In incident response circles people sometimes call it “self-attribution bias” — the reflex to assume any failure in a system you touch is caused by you touching it. It is especially strong when:
- You recently changed something nearby. (I had.)
- The change you remember is fuzzy. (It was.)
- The error mode is silent. No stack trace pointing at someone else.
- You’re the only person on the project. (Hi.)
When all four are true, you will skip the cheapest, fastest debugging step on Earth: checking whether the platform itself is broken.
That step costs nothing. It is one tab. It is status.railway.app, status.vercel.com, status.cloud.google.com. It is, in 2026, also just opening Hacker News. If a major platform is down, the front page will tell you in under a minute. It will tell you before you’ve even finished framing the question.
I did not do this. I did not do it for forty minutes.
What I actually changed about my workflow
I’m not going to pretend I’ve internalized some grand lesson. The honest version is smaller. I added a single line to the top of my mental debugging checklist, and I made it the first thing, not the last:
That’s it. Step zero. Before I read my own code. Before I think about what I changed. Before I roll anything back.
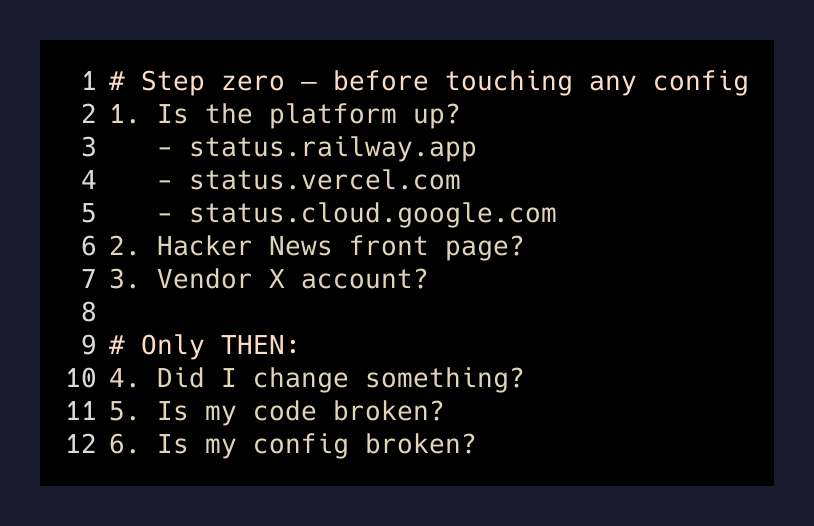
The reason this matters is not because platform outages are common — they aren’t, particularly. The reason is that the cost of checking is approximately zero, and the cost of not checking is forty minutes of confidently editing things that were fine. The expected value math is not close.
The wider pattern
I think about this a lot when working with AI tools, too. When Claude Code does something weird, my reflex is to assume my prompt was bad, my context was wrong, my MCP was misconfigured. Sometimes it is. Often the model just had a bad moment, or an upstream API was degraded, or a rate limit hit silently. The same step zero applies: before assuming you’re the bug, check if the substrate is the bug.
This isn’t an argument for blaming the platform. It’s an argument for not assuming, in the first second of an incident, that you are the only possible cause. You are a possible cause. You’re usually not the first one to check.
The story I tell myself defaults to “this is your fault” because that feels like the responsible posture. But responsibility without evidence is just a tax I pay on my own time.
Now I check the status page first. It takes nine seconds. It would have saved me thirty-nine minutes and fifty-one yesterday.